5. Les requêtes statiques et dynamique¶
Requête statique :¶
- Le navigateur envoie une requête HTTP
- Le serveur décode la demande et renvoie le fichier HTML
- Le navigateur récupère la page et l’interprète
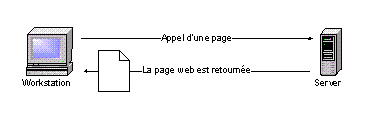
Le chargement d’une page Web est déclenché par une requête HTTP envoyée par le navigateur, depuis le client (le client étant l’ordinateur depuis lequel on souhaite afficher la page Web).
Durant le chargement d’une page, le navigateur sera amené à envoyer d’autres requêtes HTTP, notamment pour le chargement de feuilles de styles, scripts (JavaScript/JScript), images, ou objets tels que Flash ou applets Java.
Le serveur reçoit la requête HTTP. S’il trouve le fichier HTML demandé, le serveur le renvoie vers le client.
Le navigateur récupère alors le fichier.
À ce stade, le navigateur a récupéré le fichier html, il lui reste à l’interpréter. Concrètement, le fichier est lu de haut en bas, ça peut paraître évident mais cela signifie par exemple que dans un script JavaScript, des instructions hors fonctions qui seront donc exécutées immédiatement, ne pourront accéder à des éléments de la page se trouvant plus bas car ils n’auraient à cet instant pas encore été chargés.
En chargeant la page, le navigateur va transformer l’arborescence HTML en une arborescence d’objets portant le nom de DOM (Document Object Modell).
A partir du moment où la page est chargée, il n’est plus possible d’agir sur la page en manipulant le code html. Il faudra aller directement modifier les propriétés du DOM, c’est ce que l’on appelle DHTML.
Requête dynamique :¶
La page est « construite » par le serveur
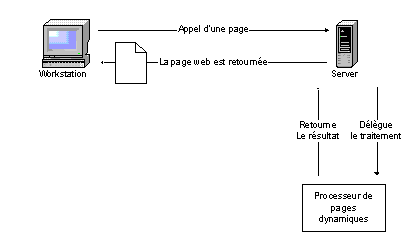
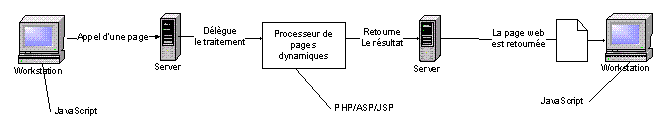
Dans une requête « statique », le serveur renvoie une page HTML existante. Mais, dans le cas d’une requête « dynamique », le serveur va renvoyer une page qui n’existe pas comme telle dans son système de fichiers: le serveur va en fait construire la page, dynamiquement, en fonction de la requête du client et du « contexte ». Ce contexte peut être défini par toutes sortes d’informations issues d’une session, d’un cookie, de l’état du serveur, de l’heure, du type de navigateur…
Déroulement d’une requête dynamique.¶
- Un processeur de pages dynamiques est le cœur du système (CGI, PERL, PHP, JSP/Servlet…).
- A noter : des traitements peuvent être exécutés sur le navigateur lui-même (JavaScript).